
Researchers at Robbyant, an Ant Group subsidiary, have just released an impressive new vision-language-action model after collecting 20,000 hours of real-world data from nine different twin arm robot setups. It’s arguably the most powerful general-purpose controller on the market, capable of handling a wide range of manipulation jobs on a variety of hardware without the need for frequent retooling.
Robbyant began with a pre-trained vision language model named Qwen2.5-VL, which is already capable of interpreting images and text. They then added an action module on top of that, which converts such understandings into accurate robotic actions. The system starts with a succession of camera views of the workspace, a natural language instruction detailing what it needs to do, and a representation of the robot’s state, including its joints and grippers. Then, in a brilliant move, it predicts what it will do next and employs a technique known as flow matching to make the control signals smooth and continuous, rather than yelling out step-by-step directions.

Unitree G1 Humanoid Robot(No Secondary Development)
- Height, width and thickness (standing): 1270x450x200mm Height, width and thickness (folded): 690x450x300mm Weight with battery: approx. 35kg
- Total freedom (joint motor): 23 Freedom of one leg: 6 Waist Freedom: 1 Freedom of one arm: 5
- Maximum knee torque: 90N.m Maximum arm load: 2kg Calf + thigh length: 0.6m Arm arm span: approx. 0.45m Extra large joint movement space Lumbar Z-axis…
The more data it collects, the better it becomes, and testing suggest that it really takes off when you get from a few thousand hours to 20,000. This is similar to the pattern seen in language models as datasets grow in size. It appears that robot intelligence may achieve the same thing if we keep feeding it more facts.
They didn’t stop there, as they also incorporated depth perception, which makes a big difference. A companion model called LingBot-Depth provides them with an accurate 3D perspective of the world, and when the two models are combined, the system improves significantly in terms of spatial judgment, distance detection, and shape recognition. In a real-world test with 100 tough tasks across three different robot platforms, the depth-augmented model dominated, outperforming its competition by several percentage points in both completion and progress criteria.
Simulator tests revealed the same result: the model remained rock solid even when subjected to a variety of random stimuli such as lighting, object locations, visual distractions, and so on. It surpassed other models by about ten points in terms of success rate. That’s significant when you’re transitioning from a controlled lab to a real-world setting.
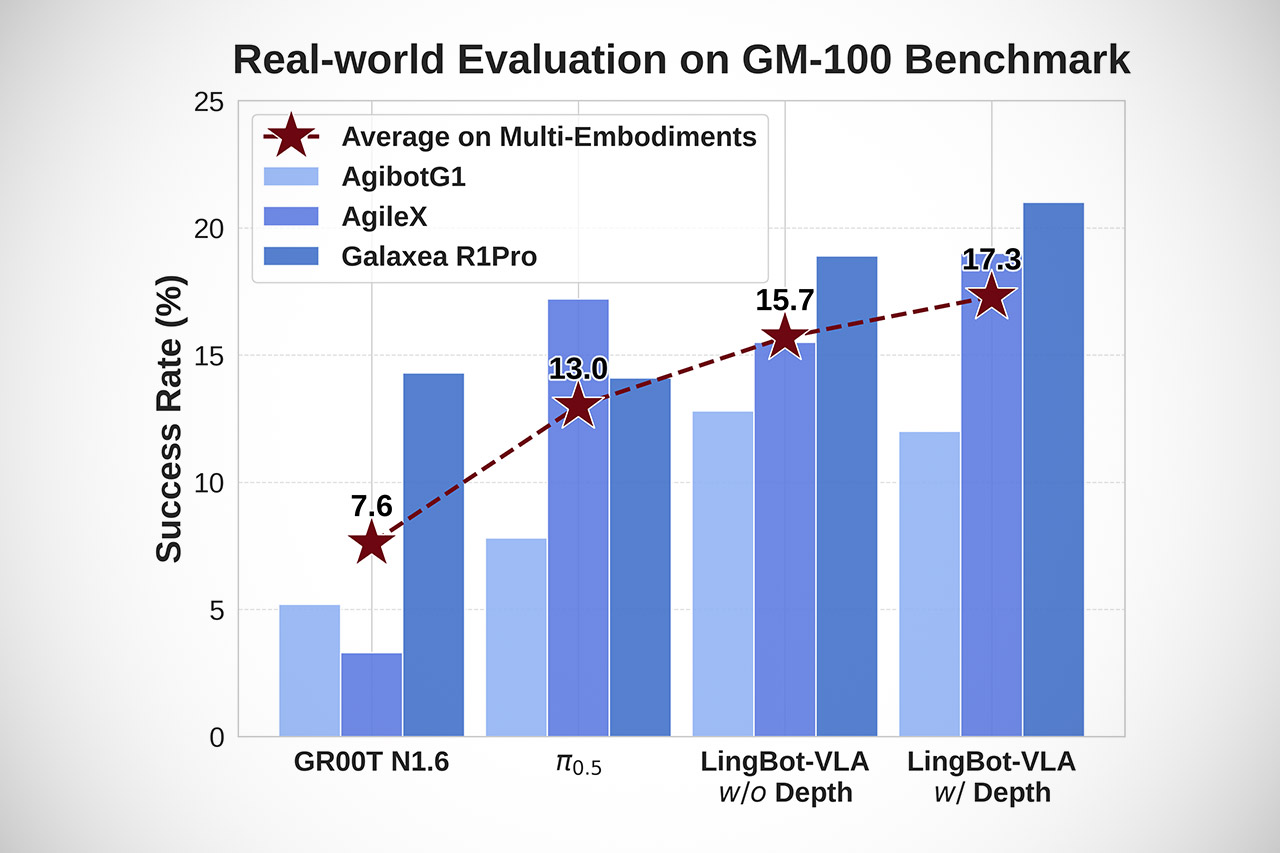
Robbyant also ensured the system was easy to train and use. The code now runs 1.5 to 2.8 times faster than rival open frameworks. Data handling, distributed processing, and low-level operator fusion have all been optimized to make training faster and more cost-effective. This should make it a lot easier for folks to try out new tasks and gear.
Adapting this approach to a new robot is actually pretty simple; all you need is a tiny display with 80 demos per task at most. Once fine-tuned, the good stuff begins to happen: performance transfers flawlessly since the foundation is already loaded with a vast knowledge base of objects, actions, and instructions. This is all made possible by the idea of having a single shared controller that can serve a variety of machines; think of it as a common software library that just gets installed on all of these different devices and requires only a small amount of configuration.
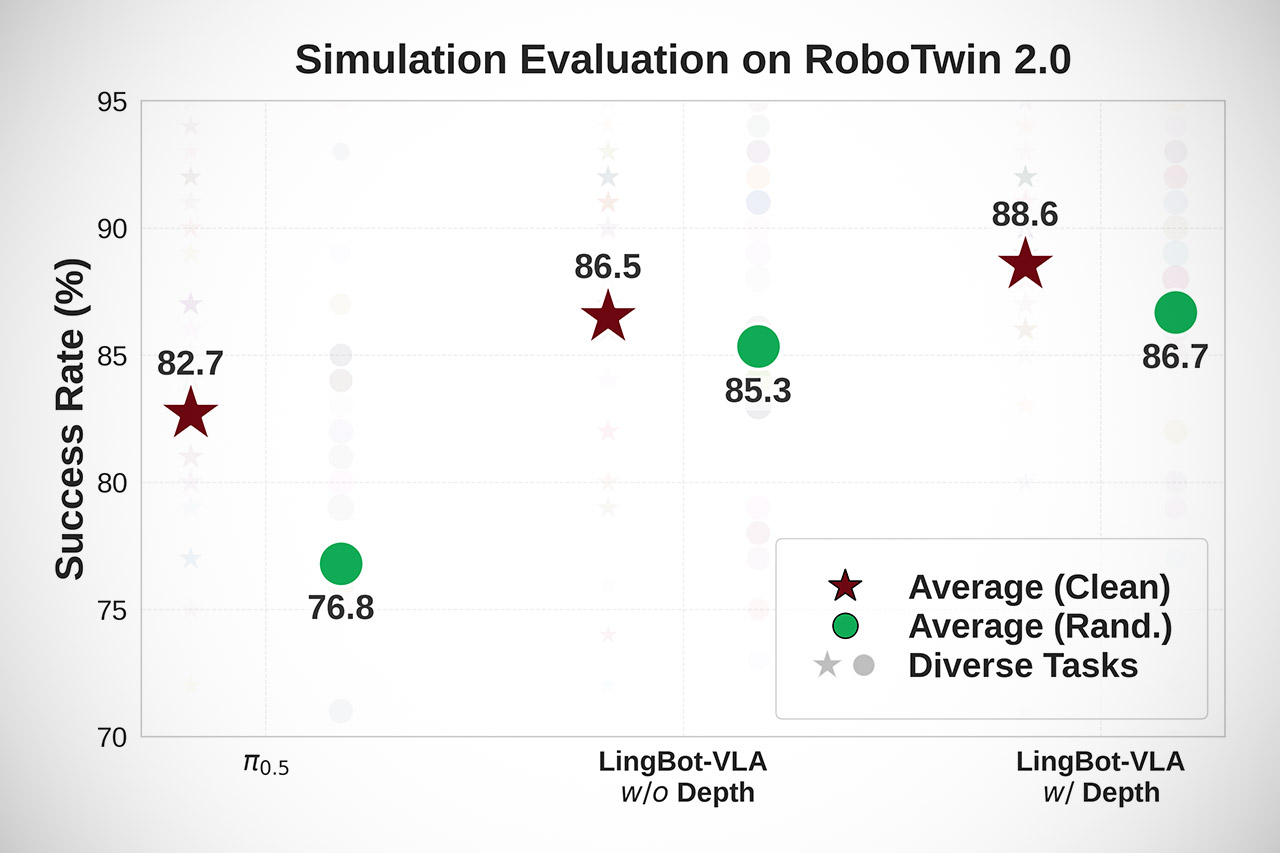
Everything is completely open now. The model weights have been applied to Hugging Face in four parameter variants, with and without the extra depth integration tossed in for good measure. We’ve also uploaded the entire training process, all of the assessment tools, and some benchmark data on GitHub, so if you want to expand on this or push the boundaries even further, you’re welcome to do so. Ant Groups researchers believe that the only way to make genuine progress with physical AI is to create models that are high-quality, transportable, and can run on a huge scale without breaking the bank.